SCOM Exchange 2013+ Addendum for Mailbox Databases and Transport Queues Health
Read More...
With Exchange 2013 Exchange Product Group has chosen a different route and implemented all the monitoring inside Exchange server which is called Exchange Managed Availability. When it comes to monitoring from Operations Manager all we have is a discovery scripts, some perf collection rules and one (yes only one) event monitor which tracks the events created by Exchange Managed Availability Service. I will not be getting into the Managed Availability and its components. As a summary it has different components called health sets and Exchange server performs ~650+ individual checks on these various components.
One of the problems of this component/service based approach is now we don’t have the visibility to individual objects like Mailbox Databases or Transport Queues. These are hidden under specific health sets. After using his management pack in many customers I wanted to do the same for Exchange 2013. I have used his techniques but I had to modify them to work with my own requirements. I have also added some extra monitors rules and added Queue monitoring. So this is what this MP is all about.
This MP will discovery individual Mailbox databases (stand alone or DAG) and Transport Queues on Exchange servers. Discovery is a PowerShell script runs against Exchange server object every 12 hours.
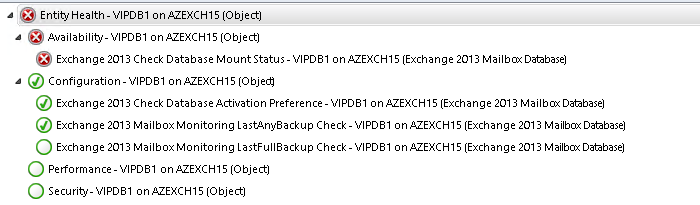
After importing the MP discovered mailbox databases can be accessed under Mailbox Database Health view under default Exchange MP folder.

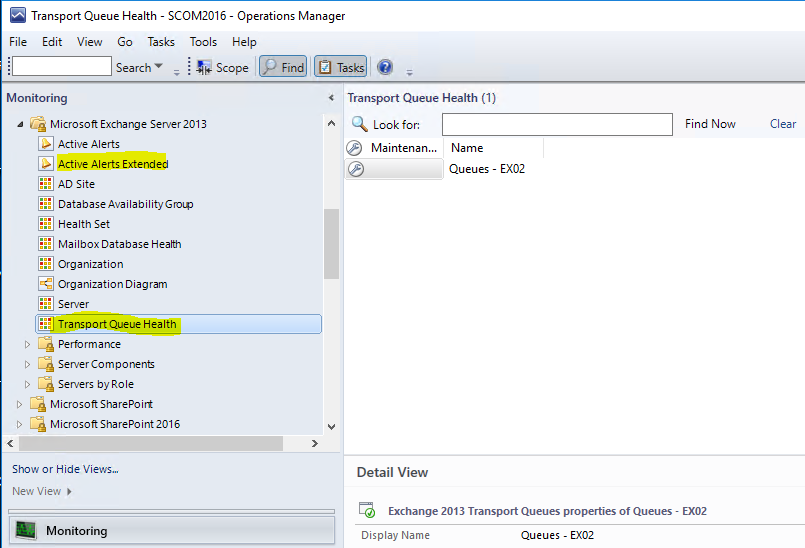
And discovered Queues can be accessed under Transport Queue Health view .
![]()
There are 3 monitors targeting to Mailbox database:
For Queues I have the following monitors configured:
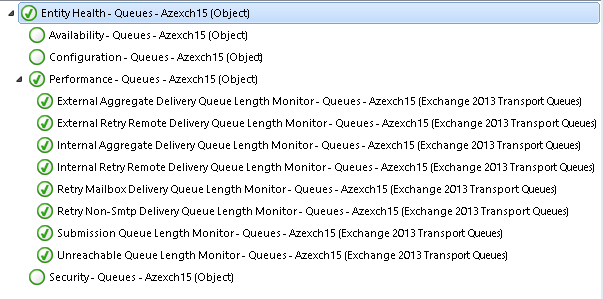
Let me remind you that all these are also monitored under Hubtransport Helath Set for the Exchange Server. So based on your requirement you might use this one or the one provided on Exchange MP.
There are 7 performance collection rules targeting to Mailbox Databases which collects:

From rules targeting to Mailbox Database you can disable the ones not needed in your organization.
There are 10 performance collection rules targeting to Queues.
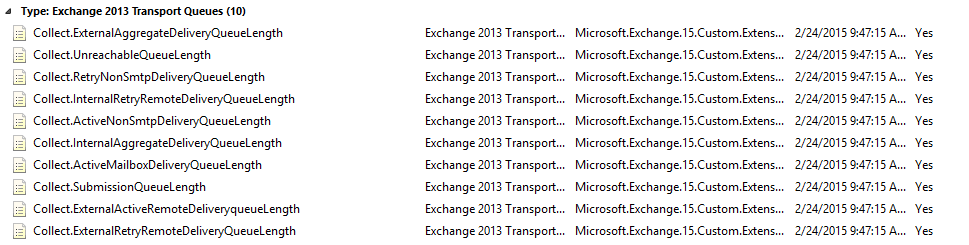
These rules can be modified by selecting Exchange 2013 Transport Queues as target(class).
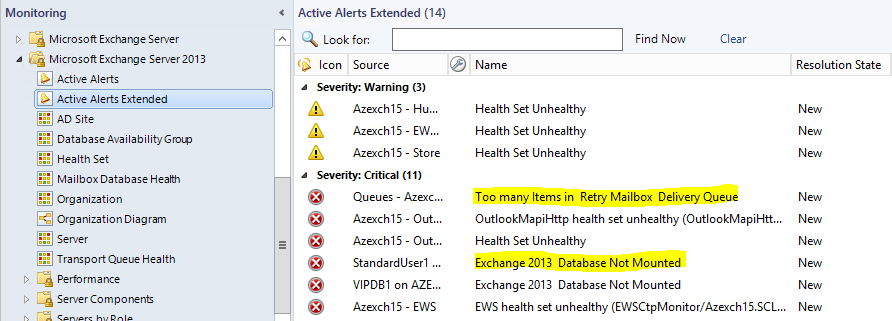
I have also created a group to include new custom objects as well as the existing one. This group is referenced in Active Alerts Extended view. You can use this view to see all alerts generated by Exchange components.
Cookdown in Operations Manager is the process of utilizing single data source to monitor multiple objects on server. On very basics if you want to monitor 10 individual database on a server you need to run your script 10 times which is very inefficient and resource consuming. So with cookdown we modify the script in a way that it outputs multiple property bags for each database we want to monitor and condition detection modules in monitors/rules take care of the rest.
So I tried to utilize this as much as possible. I share the data source in multiple rules so I have cookdown for all instances and for all rules. For database performance collections all of these rules actually retrieves data from 2 scripts. So if you have 10 mailbox database in an Exchange server instead of 10x5 = 50 scripts, I run just one which then picked up by individual rules and written to database.
The reason I have 2 script is Test mail flow script has a timeout parameter and takes longer then the rest of perf collection so this is the only reason I’ve separated it.
To get the benefit from cookdown all these rules are configured run same time by Synctime setting in MP they will run every 15 min with Synctime setting 00:00.
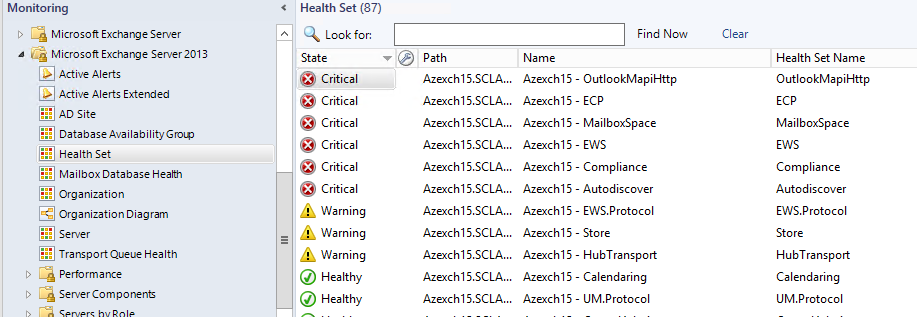
When I was developing the management pack my customer wanted the flexibility to classify health sets. In default configuration we have a two state monitor Healthy and Error . But for most customers all these health sets are not equally important. So My customer wanted to reflect Customer touch point as critical but all others as warning. We also had a second requirement where we need to use health sets in dashboards which doesn't work by default.
To overcome all these I’ve duplicated the existing event monitor and created 2 replicas. One has unhealthy state defined as warning , other as critical. These 2 monitors are targeted to Availability for the health sets and disabled by default. There are also 2 groups defined in MP;
These 2 monitors have overrides defined to enable then using these groups. . All you need to do is disable the existing monitor, add the more important health sets to Critical Health sets group and less important ones to warning health sets group.
| Management Pack | Version |
|---|---|
| Microsoft.Exchange.15.Custom.Extension | 15.0.620.239 |
 Home
Home